


This time I will take the opportunity to talk about how to calculate the COVARIANCE functions. Not only because I recently answered a question on a forum how to write and calculate the formula in SQL Server, but also since it is interesting in terms of performance. The general formula for calculating the covariance value for population is
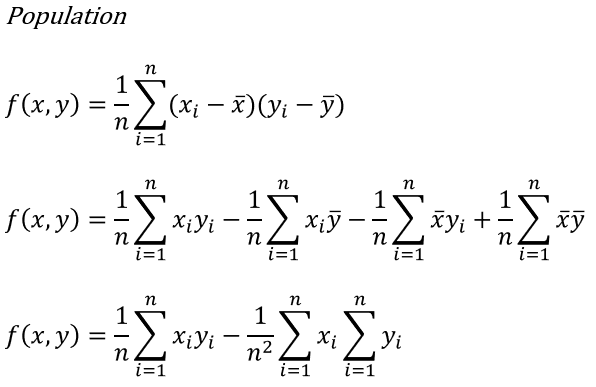
As you can see in it’s original format, the function is a two-pass operation. First calculate the average value and the subtract that average value from each row in the current dataset.
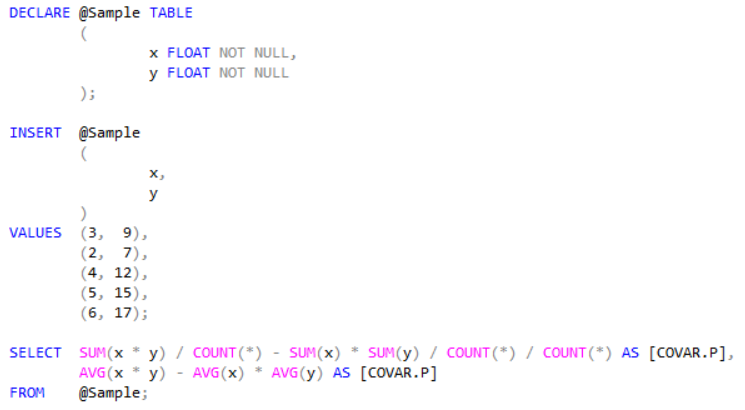
I don’t find that good in terms of performance, so I figured out how to rewrite the function to be a one pass operation.
Can we apply the same thinking again when calculating the covariance value for sample? Yes, we can.
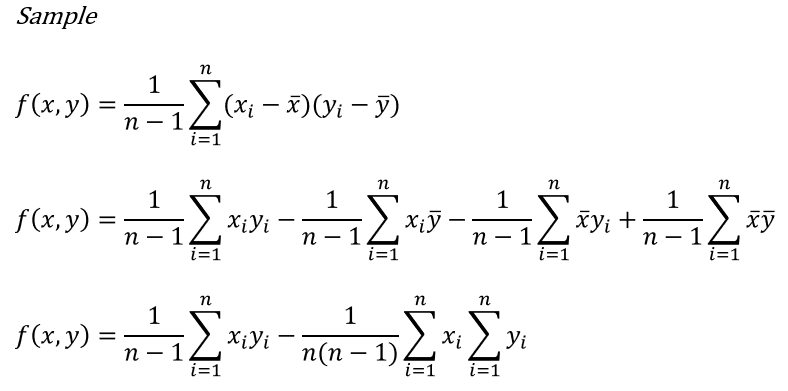
Now we have a one pass operation and we can test the formula like this
