It is not easy in XML to handle NULL values. You can of course add a custom attribute to every element to tell if the value should be NULL or not. Or, you can make proper use of the XSI:NIL attribute.
See this example

You expect think this should return two rows? One row with 0 (because empty space is converted to zero) and one row with NULL?
This is what you get.

What SQL Server need is an addition of a schema to handle NULL value.
See this example

And now you get two rows with zero. It is not really the result you expect either.
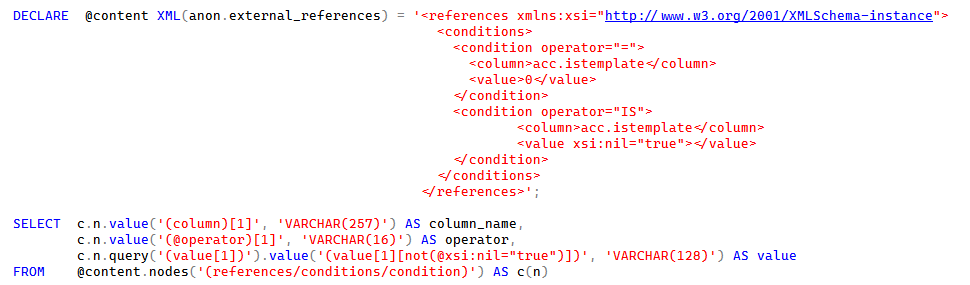
What you need is a mechanism to investigate the metadata attribute and somehow make a decision from that. This is probably the easiest way to accomplish that

And yes, we finally get the result we are looking for, one row with 0 and one row with NULL.
But think again, how often do we deal with single XML documents? Can we apply the same algorithm when the XML document is stored in a table?

This will work well. Now, what if we add an xsd-schema?

And then you get this error, even if the value element is nillable in the XSD schema.

How to get around that? By adding a xquery-function