


I recently read an article on Bitbucket about “Don’t start identity columns or sequences with large negative values” and it got me wondering if the author’s conclusion is correct.

So I set up a lab to test his hypothesis. Each table has about 4 million rows.

And to mimic the property of IDENTITY, I then rebuilt the indexes on the tables.
And then I executed these statements to see if there was a difference in compression, as the author stated.

And as I suspected, there was no difference.
The reason is how page- and row-compression is implemented.
See whitepapers here
And to be fair, I did the test again with ROW compression instead of PAGE compression and here is the result
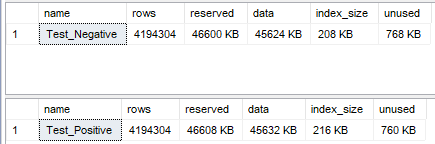
Again, there is no difference. The miniscule 8KB is within the error margin.

